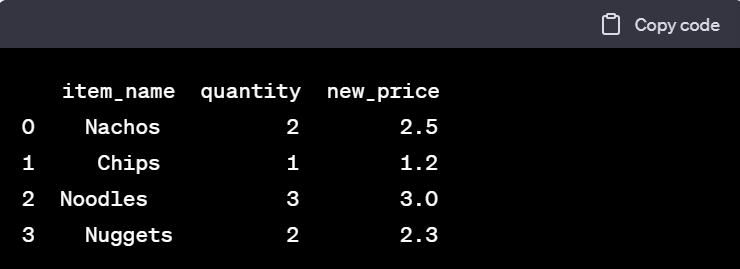
📌 groupby() 메서드 데이터를 그룹화하여 연산을 수행하는 메서드 입니다. 형태 : DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True) 사용법 by : 그룹화할 내용입니다. 함수, 축, 리스트 등이 올 수 있음 axis : 그룹화를 적용할 축 level : 멀티 인덱스의 경우 레벨을 지정할 수 있음 as_index : 그룹화할 내용을 인덱스로 할지 여부/ False이면 기존 인덱스가 유지됨 sort : 그룹키를 정렬할지 여부 group_keys : apply메서드 사용시 결과에 따라 그룹..